Working with GPU#
The KI4All-Cluster provides a number of high-performance GPUs on which simulations can be run in the context of research and student projects. The resources on the cluster are managed by the Slurm Workload Manager (short: Slurm). Simulations are run on the cluster in SingularityCE (short: Singularity) containers, which package up your software together with all required dependencies. This makes your software portable, reproducible and independent of the operating system.
In the following sections, we give an introduction to Slurm. However, it is necessary that you also deal with the referred documentations.
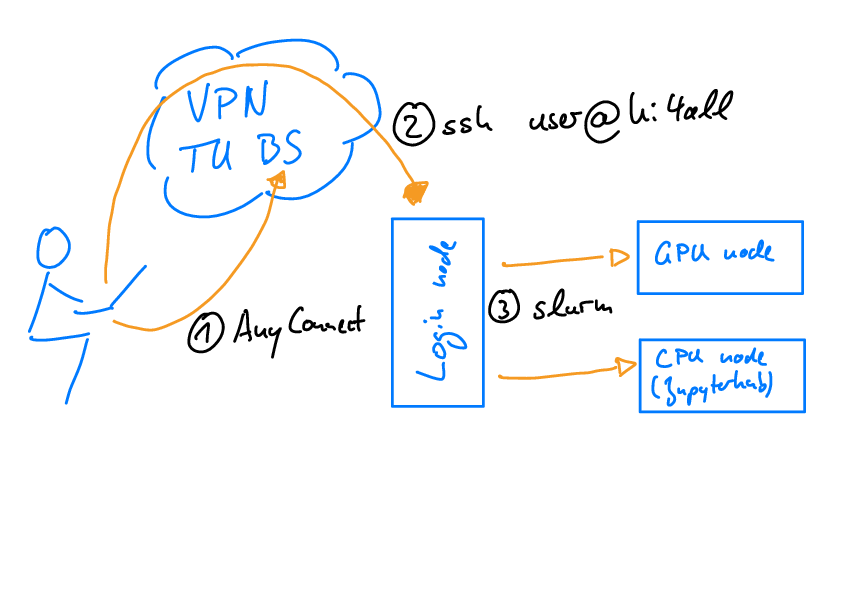
Fig. 3 Accessing the KI4All Cluster: (1) The cluster can only be reached within the university network. When working from home, you need to establish a VPN connection. (2) You log in to the login node via ssh. (3) On the login node, start your computations on the CPU or one of the available GPU nodes via slurm.#
Note
Running code on the cluster requires basic knowledge of using your terminal. There is another chapter in this Knowledge Base on this topic which might be helpful.
Log in to the Cluster#
In order to run your simulation on the cluster, you must first log in to the cluster using SSH with the following command:
$ ssh username@ki4alllogin.irmb.bau.tu-bs.de
You will then be prompted to enter your password. To log in, please use the username and password of your TU Braunschweig account, which you also use to log in to other TU Braunschweig services, such as Stud.IP.
About Slurm#
Slurm Workload Manager (short: Slurm) is a cluster management and job scheduling system for large and small Linux clusters [1].
In this section, we list the most important commands for submitting Slurm jobs on the cluster. In addition, we show a minimal example for a Slurm job script. For a complete documentation including all commands and covering more edge cases, we refer to [1].
Most Important Commands#
Submit a job:
$ sbatch example.sh
The Slurm job is defined in a shell script (here: example.sh). In the next subsection, there is a minimal example for a Slurm job script.
Report the State of Submitted Jobs:
$ squeue
This command informs you, among other things, about the status of your job (R=running, PD=pending, C=canceled) and how long it has been running.
Cancel a Job:
$ scancel job-ID
Each job has its own job ID. You get the ID of your job as terminal output when you submit the job. You also get the IDs of your jobs by executing the queue command (see above).
Note
In the Slurm documentation [1], you will find many more commands that might be helpful in some cases. In addition, some commands have additional filtering, sorting and formatting options which are also listed in the referred documentation.
Example Slurm Job Script#
Here is an exemplary Slurm job script:
#!/bin/bash
#SBATCH --partition=gpu_teaching
#SBATCH --nodes=1
#SBATCH --time=1:00:00
#SBATCH --job-name=test
#SBATCH --ntasks-per-node=1
#SBATCH --gres=gpu:ampere:1
singularity exec --nv example.sif python example.py
The first line #!/bin/bash is strictly necessary so that the shell interprets the Slurm job file correctly. The following lines define, among other things, how many resources Slurm should allocate for the job. The required resources etc. are defined via options, which are always preceded by #SBATCH.
A list of the most important options follows:
Option |
Description |
|---|---|
|
Sets the partitition (queue) to be used, see also the paragraph Queues below. |
|
Sets the number of nodes to be used. (On the KI4All-Cluster, only one node is available.) |
|
Sets the maximum time the job runs before being cancelled automatically. The default is 1 second (unless otherwise specified in the the job script). The maximum allowed time is 1 day in the gpu_teaching partition and 14 days in the gpu_irmb_full and gpu_irmb_half partitions. |
|
Sets the job name. This is also displayed when the status of the job is queried with the command |
|
Sets the number of tasks to be run per node. This becomes interesting if parallel computations are to be performed on the node. |
|
Specifies a comma-delimited list of generic consumable resources. The format of each entry on the list is name:count. The name is that of the consumable resource (see also paragraph Generic Consumable Ressources (GRES)). The count is the number of those resources (defaults to 1). When submitting Slurm jobs on the KI4All-Cluster, under normal circumstances, you can include this option unchanged in your script. |
The last line defines what the job should do. In this case, the Python script example.py is to be executed in the Singularity container example.sif. An introduction to Singularity can be found in the previous section.
Note
There are some other options that might be helpful for you in some cases. For a complete list of all options and their meaning, we refer to [1].
Queues#
On the KI4All-Cluster, all users belong to a user group through which permissions are regulated. The user group also determines which partitions you can use on the cluster. Basically, a distinction is made between the following three user groups:
The user group
betreiberconsists of the employees of the Institute for Computational Modeling in Civil Engineering (iRMB) at Technische Universität Braunschweig.The user group
internconsists of the members of the KI4All-Project.Separate groups are added for each of the lectures that work on the cluster, which are further summarized under
teaching.
You can specify the partition (queue) to which you want to submit your Slurm job in the job script with the --partition option (see above). Below you will find a detailed list of all partitions of the KI4All-Cluster with their exact names and the assignment of user groups that have permission to use the partition.
Partition |
Permitted User Groups |
|---|---|
gpu_teaching |
|
gpu_irmb |
|
Generic Consumable Ressources (GRES)#
Which generic consumable ressources (gres) are available to you depends on the partition (queue) in which you submit your job. You specify the gres you want to use for your job in the Slum script with the --gres option (see above). Below you will find a tabular list of the exact names and numbers of generic consumable ressources (gres) available in the respective partitions.
Partition |
GRES |
Number |
Description |
|---|---|---|---|
gpu_teaching |
gpu:ampere |
3 |
Nvidia A100 80GB |
gpu_irmb |
gpu:ampere |
5 |
Nvidia A100 80GB |
Note
It is essential that you correctly name the gres in your job script and only request the gres that are also available in the partition used. A detailed list of the partitions and available gres can be found above. If unavailable gres are requested, an error message will appear on the terminal and the job will not be submitted.
Further Help#
In addition to the documentation [1], you can get more help for each command and a list of all available options by entering the following command in the terminal:
$ command --help
References:#
Reference |
|
|---|---|
[1] |
Slurm Workload Manager Documentation, last modified 5 Octobre 2022, accessed 8 february 2023, https://slurm.schedmd.com/documentation.html |